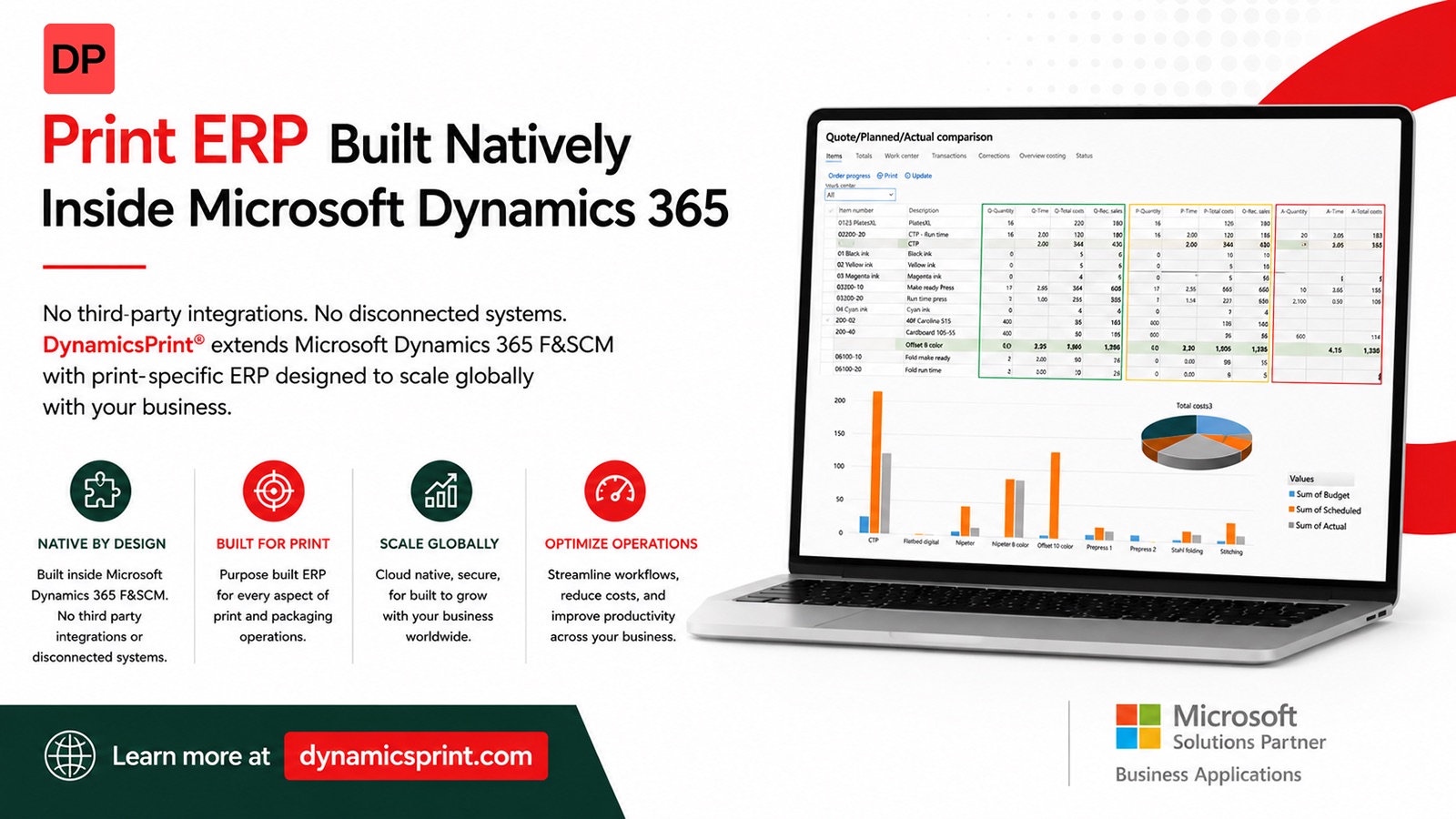
By Chuck Gehman October 20, 2003 -- By some estimates, there are more than 200 Variable Data Printing (VDP) tools and products on the market today. They all employ different approaches to solve essentially the same set of problems. But there is an important piece missing if we are to achieve the widespread adoption sought for these technologies, and to spur the long-anticipated growth in the VDP marketplace. The biggest problem with VDP today is that it is not a designer-friendly process, for a number of important reasons. This general premise has been stated before, but the real reasons behind lack of adoption of variable print strategies by designers may have been overlooked. Let's face it: designers typically use only one or two document creation programs. This is a generalization, certainly, but most designers I know (including my wife) are experts in one or two of the following applications: Quark (increasingly Adobe InDesign), Photoshop and/or Illustrator (yes, there are a lot of FreeHand users out there, too.) In my experience, designers tend to ocus on one primary application they like to work in and use the other application to “help” when they need to overcome a particular tactical issue. If designers only want to focus on their “primary” application, then asking them to use complicated and cumbersome (and just as importantly, more than one) applications to design a product that will incorporate variable printing, then we, as an industry, are creating some major barriers to adoption. It's about the process Think about the convoluted work process. First documents must be converted documents from their original application to a format that will work with whatever VDP tool is employed. Next, designers have to learn use of a tool that is compatible with the ultimate output provider's software (or perhaps, their RIP and/or press). In addition to the mechanical preparation of the file, there is a need to learn how to build business rules that control how the final documents will behave when combined with the data. Finally—and perhaps overshadowing even the daunting obstacles presented by the first two issues—is access to “real” data sources, so designers can see what the printed product they are designing will actually look like once it is produced. It is a rare designer who is also a database guru. Virtually all of the solutions available today require that documents be re-created to incorporate variable data. Even products that make it easier than entirely re-creating a document from scratch are limited in the types of documents they will “import” to turn source application documents into template-driven VDP documents. Some solutions incorporate plug-ins to desktop publishing applications like Quark, while others either read EPS files or PDF files, and still others are Adobe Acrobat plug-ins that modify PDF files. But we're not done yet After you've overcome the complexity of “marking up” the document with “tags” (I use these terms generically to describe the process of “variable-izing” the document, because the different vendor approaches necessitate different terminology as well as actual processes), the designer is still faced with the problem of having to anticipate variations in the input data that will need to be handled by business rules at the time the documents are combined with the data. These business rules may be as simple as dictating how the document should behave when an address has two lines versus three (i.e., move the line up), or what to do when one line is too long (a name on a business card, for example), or more complex issues such as how to re-flow a block of text to move from one page to the next when the “story” is longer than will fit on one page. In an ideal world, the best way for a designer to lay out a document and to build the business rules would be to give them access to the actual data source. If the data is sitting in a CSV (Comma Separated Values) text file on the designer's desktop, this is simple to accomplish. But that's only practical for small databases. When the data resides in a secure corporate data warehouse controlled by the IT department, this is clearly not an option. Many corporations have strict privacy policies that forbid the designer from actually seeing the real data. The challenge is to provide the designer what they need, while at the same time supporting the needs of corporate client and their IT capabilities. PODi (The Print On Demand Initiative, www.podi.org ), has gone a long way toward standardizing the back-end processes involved in the production of VDP with the deep and remarkable PPML (Personalized Print Markup Language), an XML-based specification that has been widely adopted by industry suppliers and seems to be on its way to virtually replacing the proprietary languages and coding schemes that output vendors have used in the past. But it seems that PPLM may solve only half of the problem. There must be an easy, standardized way to create “personalizable” VDP documents from popular input file formats or within native applications that designers already know how to use. There must be a way to make it easy to create and test the business rules that are used to insert data into those documents. And we must find a way to provide either access to real data sources or effectively simulate such data. Otherwise, the applications and the user community will continue to be limited, and the much ballyhooed “explosion” of the VDP market will never occur.